LAUGHTON ELECTRONICS |
||
|
|
||
|
|
Memory-space Commentary |
|

|
Before moving on, it's worth appraising Kimklone memory addressing as compared to other approaches used to expand existing 8-bit architectures. KK's 16Mbyte addressing is nimble and programmer- friendly — much in contrast with the ubiquitous alternative, a Memory Management Unit. One MMU shortcoming is that there's a 64K limit to how much you can "see" at a time. I/O operations to the MMU are required anytime you want to update the mapping to show something not already visible. Even the most sophisticated MMUs suffer from this. KK minimizes the problem in two senses. First, KK updates have less impact on performance because a Pointer Register load — a single KK instruction — is speedier than an I/O sequence to an MMU. Second, there may be less need to perform updates, for the following reason. Although there's still a limit to how much you can see at a time, the amount is quadrupled since KK's Pointer Registers make four entire 64K banks available at once. These advantages alone
are
significant, but there's a far more important point to discuss. |
|
Using Linear Addresses and Large Arrays |
||
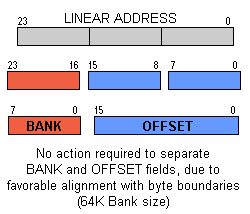 Address processing is unnecessary with 64K Banks (above), as compared with other sizes such as 32K (below). 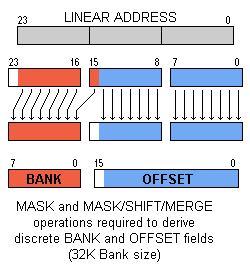 |
The crucial aspect of KK's 64K banking scheme is that it's amenable to run-time address calculation — the sort of processing sometimes called "pointer arithmetic." Compared with, say, 32K chunks, KK's 64K chunks are easier to deal with, and about ten times faster to prepare addresses for. They are the key to efficient linear addressing of large structures. To illustrate, let's imagine we have a data array in memory. The total size is several megabytes, and our program needs to step from one element to the next (as part of a search, perhaps). As usual with 65xx programming, there'll be a pointer maintained in zero page. So, to move from one element to the next, we simply add Element_Size to the zero-pg pointer. (The addition will be 24-bit since Element_Size may exceed 64K. In any case it takes a 3-byte pointer to address our 16MB space.)Having computed the new 24-bit address, we find the legacy architecture has no direct means to accept it. We need to separate the address into two fields: bank and offset. That's a trivial matter for KK's 64K chunks: the bank "field" is simply the most-significant byte of the three-byte address, and the other two bytes are the offset. To use the 24-bit address all that's necessary is to load a Pointer Register with the most-significant byte; then the application code proceeds to use Far versions of any of the Zero-Pg-Indirect instructions (referencing the two-byte "offset" field.) But, if we rewind and try all that with non-64K chunks, we find that separating the bank and offset fields is no longer a trivial matter! That's because the fields don't neatly fit on byte boundaries (see diagram, left). We're forced to insert a LOT of extra code to separate the fields. For the offset we need a load operation, a mask then a store back to Zero Page. The bank field typically requires a load-mask-shift-store that produces a partial result; this is followed by a final load-shift-merge and a store to the MMU. By the time the actual memory access can proceed, the overhead has mushroomed to dozens of cycles. In contrast, the KimKlone's extra overhead for a Far access is just three cycles to load a Pointer Register plus one cycle if the Far operation requires a prefix. Admittedly, some coding scenarios have no requirement for efficient linear addressing (or even inefficient linear addressing). For example an MMU approach is quite satisfactory for goals like switching portions of a System ROM in and out of a 64K address space. And there's no doubt that an MMU can make it possible to address very large amounts of memory. But what an MMU scheme lacks is the ability to rapidly make use of 24-bit addresses which are computed at run time. Such computations occur in copious abundance if your program is the sort that deals with multi-megabyte structures. The ability to field that challenge is what puts the KimKlone in a different class from MMU-enhanced 8-bit machines. In the next section we'll
look at KimKlone instruction
encoding. |
|
| < Previous Page KK Index Next Page > | ||
| visit LAUGHTON ELECTRONICS |
Home Commercial& Manufacturing Stage&Studio Laboratory&OEM |
|
") |
||