LAUGHTON ELECTRONICS |
||||||||||||||||||||||||||||||||||||||||||||||||||
The KimKlone: Bride of Son of Cheap Video |
||||||||||||||||||||||||||||||||||||||||||||||||||
A “Smart” Register for 6502 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
6502 programs frequently use a pair of zero-page bytes as a pointer for indirection. But incrementing that 16-bit memory-resident pointer is rather slow, and the alternative (ie, Indirect-Y post-indexing) is faster but has certain limitations. What would be ideal is a pointer that can do 16-bit increments on itself. The KimKlone has a pointer register that can do just that. Although four '163's, a pair of '244's and some glue logic would've done the job, I saved board space (and amused myself immoderately) by handing the job over to an unused 16-bit counter/timer in one of the KimKlone's VIA's. (VIA, or versatile interface adapter, is Marketing-Speak for a 65C22 multi-function peripheral chip.) The VIA was mapped into zero-page anyway, and there was nothing to prevent it, an I/O device, from playing the role of a couple of bytes of RAM. (But somehow I doubt that the VIA's designers ever dreamed that their counter/timer might find use as an indirect pointer for addressing memory!) To do this, a program first stores the initial address into the VIA's T2Low and T2High counter registers, exactly as quickly and easily as it might do using a couple of bytes of ordinary zero-page memory. The difference is that, after each indirect access (pointing via the VIA, so to speak), the pointer can be single- or double-incremented across all 16 bits using just a SINC or DINC instruction. The microcode for these merely tickles VIA pin 16, configured as the input to the counter. That's all that's required to advance the pointer so it'll indicate the next byte or word to be accessed. SINC and DINC are dramatically faster than conventional code that does the same job. SINC takes 2 cycles, whereas the equivalent would consume at least 8. DINC, also 2 cycles, replaces code that would take at least 13 — not too shabby a boost, for a pointer-increment operation that gets worked to death in the run-time hot-spots of many common algorithms! But there's an even stronger reason why I wanted an auto-increment register, and why I gave it even more capability. Forth and Hardware-Accelerated NEXTThe KimKlone's ultimate gnarliness, and the most elaborate of all the deceitful pranks played on its long-suffering CPU, is the operation called NEXT. NEXT is what a Forth computer does in order to update its program counter (aka Interpretive Pointer) and fetch its next Forth instruction. KK doesn't execute Forth operations directly. Instead, a virtual Forth computer is made available via simulation. (Actual Forth computers do exist, but simulation is a viable and common alternative.) It's easy to see that NEXT — an operation that needs to execute as part of every Forth instruction — could easily become a peformance bottleneck. So, in order to perform efficiently, the KK's virtual Forth machine uses the auto-increment register, mentioned above, as IP. Associated with each increment is a jump to one of the 6502 code snippets that simulate Forth instructions. The succession of jumps is called threading, and the threaded interpreter for KK's simulation is modelled after FIG-Forth. FIG (Forth Interest Group) Forth uses a common variant known as indirect-threaded code, or ITC. That means when NEXT fetches a pseudo-instruction pointed to by the IP, what's fetched is a pointer to a pointer to executable host-CPU machine-code. On an unassisted 65C02, simulating indirect-threaded NEXT takes about a dozen instructions and consumes roughly 40 cycles.The KimKlone has a one-byte instruction that executes ITC NEXT in just 9 cycles. KK NEXT expands into two Jump instructions chained together, plus the pointer increment mentioned above. The actual play-by-play is spelled out below for anyone who's nerdy enough to wonder; the rest of you may choose to skip ahead to the following page. KimKlone Accelerated NEXT: just a little shell game |
|||||||||||||||||||||||||||||||||||||||||||||||||
|
|
To be
clear, here's how
the stage is set.
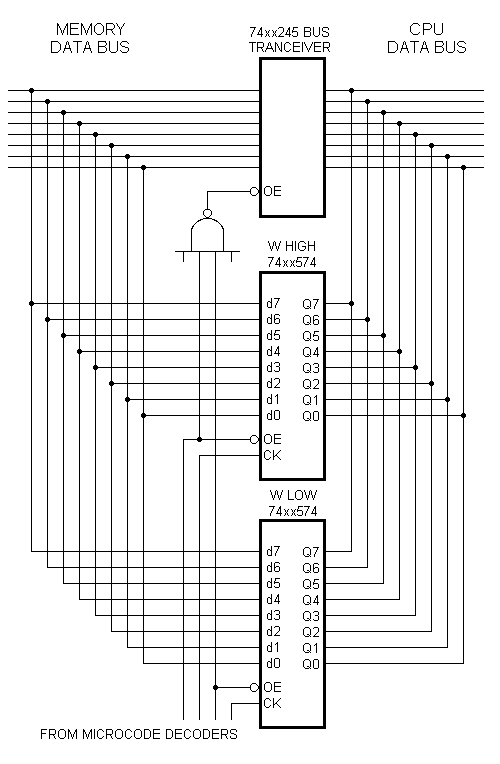
• The IP (Interpretive Pointer -- Forth's program counter) holds the address of the next Forth "instruction" to execute. A fetch via the IP will return the "instruction." • the "instruction" is just an address. Dubbed the Code Field Address (CFA), it indicates part of the header of the Forth word's definition. A fetch via the CFA will return the so-called Code Field (CF). • the Code Field needs to go in the 65xx Program Counter — it's the address of the machine code routine which simulates the desired Forth operation. The KK op-code for NEXT is 3Bh — one of the xxxxx011 codes and therefore subject to substitution. When 3B is fetched in cycle 1 the alias fed to the CPU is 4Ch, the op-code for a JMP Absolute. (See row 1 of the Table, lower left.) In cycles 2 and 3 the CPU continues fetching, expecting the 4C op-code to be followed by a two-byte operand indicating the destination of the jump. Microcode intervenes, and what gets jammed onto the CPU bus is the value in the IP. (Microcode has hooks into the VIA chip-select logic that can override the usual address decoding and cause T2Low or T2High to be coughed out onto the bus at any time.) Three cycles have elapsed, and the op-code 3Bh got spoofed into a JMP IP@. But there's no 65xx machine code at IP@, just a Forth instruction/CFA. Now comes the other half of the operation: In cycle 4 the CPU tries to execute the CFA, but the disconnect between the data buses still prevails. The low-byte of the CFA is copied from the memory bus to one of a pair of 74HC574's that form the KK register known as W (see the diagram, left). Simultaneously in cycle 4 another circuit (not shown) drives the CPU bus with 6Ch — the op-code of the JMP Absolute Indirect instruction. The CPU continues fetching, expecting the 6C to be followed by a two-byte operand. And what it receives in cycles 5 and 6 are the CFA bytes that were fetched onto the memory bus in cycles 4 and 5! KK uses the bytes of the W register to simulate a FIFO buffer, delaying the CFA bytes so the 6C op-code can be inserted ahead of them in the stream reaching the CPU. Preceded by 6C, the CFA makes perfect sense! All the rest is routine.
In cycles 7, 8 and 9 the
CPU — free of meddlesome interference at last!
— uses the CFA to fetch the two bytes of the CF
into its PC, thereby effecting a jump to the simulation routine. (The
65C02 wastes one cycle during this process.) Cycle
10 will be the first op-code fetch of the simulation code.
Microcode has finished double-incrementing IP by this
time, and W conveniently retains the CFA, from which other
fields in the word header can be indexed. Compared with a software-only approach, KimKlone more than quadruples the speed of NEXT. The scheme relies largely on microcode circuitry already included for the 16 MByte memory addressing. |
|||||||||||||||||||||||||||||||||||||||||||||||||
| <Previous Page KK Index Next Page > | ||||||||||||||||||||||||||||||||||||||||||||||||||
| visit LAUGHTON ELECTRONICS |
Projects Servicing the unserviceable Main/extra index |
|||||||||||||||||||||||||||||||||||||||||||||||||
") |
||||||||||||||||||||||||||||||||||||||||||||||||||